Research Highlights
Learning-augmented Stochastic Networks Optimization
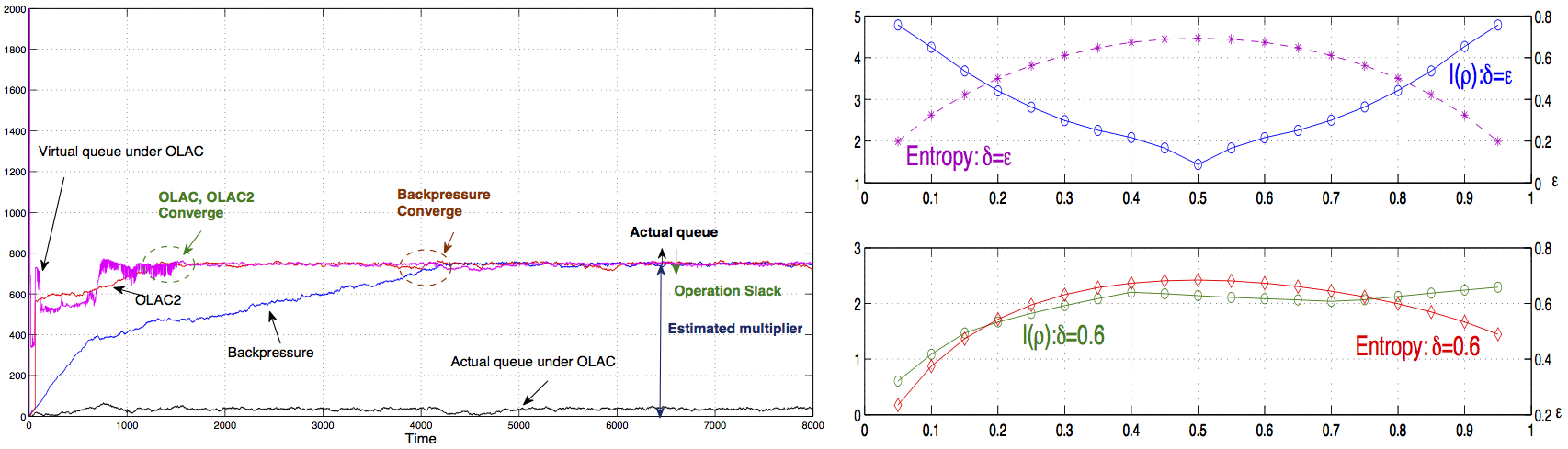
Existing network optimization results have mostly been focusing on designing algorithms either based on full a-priori statistical knowledge of the system, or based on stochastic approximation for systems with zero knowledge beforehand. These two scenarios, though being very general, do not explicitly capture the role of information learning in control and do not reap the potential benefits of it. This ignorance often leads to a mismatch between algorithms in the literature and practical control schemes, where system information (data) is often constantly collected and incorporated into operations.
In this research thrust, we are interested in (i) quantifying fundamental benefits and limits of learning in network optimization, and (ii) designing simple and practical algorithms for achieving the full benefits.
 |
Representative publications:
Yan Dai, Longbo Huang, ‘‘Adversarial Network Optimization under Bandit Feedback: Maximizing Utility in Non-Stationary Multi-Hop Networks,’’ Proceedings of ACM Sigmetrics (Sigmetrics), June 2025. (Best Paper Award)
J. Huang, L. Golubchik, L. Huang, “When Lyapunov Drift Based Queue Scheduling Meets Adversarial Bandit Learning,” IEEE/ACM Transactions on Networking (TON), vol. 32, issue 4, pp. 3034-3044, August 2024.
P. Hu, Y. Chen, L. Pan, Z. Fang, F. Xiao, L. Huang, “Multi-User Delay-Constrained Scheduling with Deep Recurrent Reinforcement Learning,” IEEE/ACM Transactions on Networking (TON), vol. 32, issue 3, pp. 2344-2359, June 2024.
[Book] L. Huang, “Learning for Decision and Control in Stochastic Networks”, Synthesis Lectures on Learning, Networks, and Algorithms, Springer Nature, June 2023.
L. Huang, ‘‘Fast-Convergent Learning-aided Control in Energy Harvesting Networks,’’ IEEE Transactions on Mobile Computing (TMC), vol. 19, no. 12, pp. 2793-2803, December 2020.
K. Chen and L. Huang, “Timely-Throughput Optimal Scheduling with Prediction,” IEEE/ACM Transactions on Networking (TON), vol. 26, issue 6, pp. 2457-2470, December 2018.
K. Chen and L. Huang, “Timely-Throughput Optimal Scheduling with Prediction,” IEEE International Conference on Computer Communications (INFOCOM), April 2018. (Invited for Fast-track Review at IEEE TNSE (7/1600+ submissions))
L. Huang, S. Zhang, M. Chen, and X. Liu, ‘‘When Backpressure meets Predictive Scheduling,’’ IEEE/ACM Transactions on Networking (TON), vol. 24, issue 4, pp. 2237-2250, August 2016.
M. Hajiesmaili, C. Chau, M. Chen, and L. Huang, ‘‘Online Microgrid Energy Generation Scheduling Revisited: The Benefits of Randomization and Interval Prediction,’’ Proceedings of ACM e-Energy (e-Energy), June 2016. (Best Paper Runner-up)
L. Huang, S. Zhang, M. Chen, and X. Liu ‘‘When Backpressure meets Predictive Scheduling,’’ Proceedings of 15th ACM International Symposium on Mobile Ad Hoc Networking and Computing (MobiHoc), August 2014. (Best Paper Candidate)
L. Huang, X. Liu, and X. Hao, ‘‘The Power of Online Learning in Stochastic Network Optimization,’’ Proceedings of ACM Sigmetrics (Sigmetrics) (full paper), June 2014.
L. Huang and M. J. Neely, “Delay Reduction via Lagrange Multipliers in Stochastic Network Optimization,” IEEE Trans. on Automatic Control (TAC), Volume 56, Issue 4, pp. 842-857, April 2011.
Online Learning and Reinforcement Learning
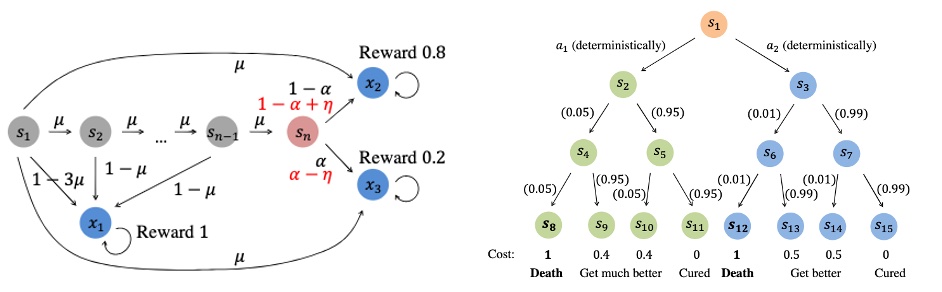
Sequential decision making is a fundamental problem that receives extensive attention in various areas. However, existing frameworks and algorithms often focus on maximizing the cumulative reward, and ignore the safety and robustness aspects. As a result, in many risk-critical scenarios, e.g., finance and autonomous driving, the risk-neutral results cannot be directly applied.
In this thrust, we are interested in designing safe and robust decision making algorithms. We focus on risk-sensitive RL and robust online learning and aim to develop efficient algorithms with strong performance guarantees.
 |
Representative publications:
Yu Chen, Yan Dai, Jiatai Huang, Longbo Huang, ‘‘uniINF: Best-of-Both-Worlds Algorithm for Parameter-Free Heavy-Tailed MABs,’’ Proceedings of the Thirteenth International Conference on Learning Representations (ICLR), April 2025. (Spotlight)
Yu Chen, Xiangcheng Zhang, Siwei Wang, Longbo Huang, “Provable Risk-Sensitive Distributional Reinforcement Learning with General Function Approximation,” Proceedings of the Forty-first International Conference on Machine Learning (ICML), July 2024.
Tonghe Zhang, Yu Chen, Longbo Huang, “Provably Efficient Partially Observable Risk-sensitive Reinforcement Learning with Hindsight Observation,” Proceedings of the Forty-first International Conference on Machine Learning (ICML), July 2024.
Yu Chen, Yihan Du, Pihe Hu, Siwei Wang, Desheng Wu, Longbo Huang, “Provably Efficient Iterated CVaR Reinforcement Learning with Function Approximation and Human Feedback,” Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024.
Nuoya Xiong, Yihan Du, Longbo Huang, “Provably Safe Reinforcement Learning with Step-wise Violation Constraints,” Proceedings of the Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS), December 2023.
Jiatai Huang, Yan Dai, Longbo Huang, “Banker Online Mirror Descent: A Universal Approach for Delayed Online Bandit Learning,” Proceedings of the Fortieth International Conference on Machine Learning (ICML), July 2023.
Yihan Du, Siwei Wang, Longbo Huang, “Provably Efficient Risk-Sensitive Reinforcement Learning: Iterated CVaR and Worst Path,” Proceedings of the Eleventh International Conference on Learning Representations (ICLR), May 2023.
J. Huang, Y. Dai, L. Huang, “Adaptive Best-of-Both-Worlds Algorithm for Heavy-Tailed Multi-Armed Bandits,” Proceedings of the 39th International Conference on Machine Learning (ICML), July 2022.
T. Jin, L. Huang, H. Luo “The best of both worlds: stochastic and adversarial episodic MDPs with unknown transition,” Proceedings of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS), December 2021. (Oral, top 1%)
Deep Reinforcement Learning
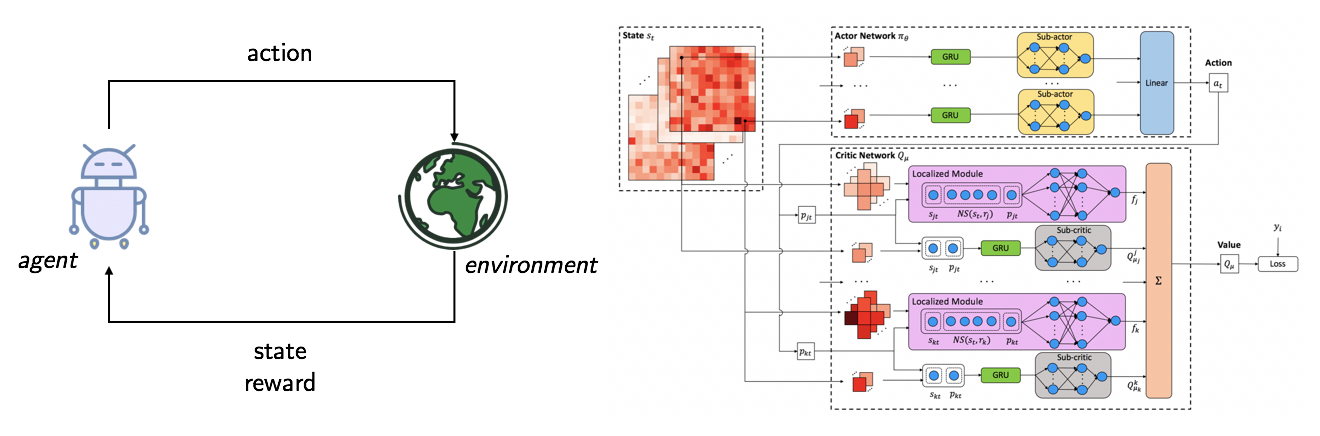
Deep reinforcement learning (DRL) has achieved groundbreaking success for many decision making problems, both in discrete and continuous domains, including robotics, game playing, and many others. In reinforcement learning, an agent does not have access to the transition dynamics and reward functions of the environment. Therefore, it learns an optimal policy by interacting with the unknown environment, which can suffer from high sample complexity and limited applications in high-dimensional real-world problems. Therefore, it is important for the agent to find efficient and practical ways for learning.
In this research thrust, we are interested in (i) designing efficient and practical DRL algorithms in specific domains, and (ii) improving the performance and generalizaiton of DRL algorithms for general tasks.
 |
Representative publications:
Xun Wang, Zhuoran Li, Longbo Huang, ‘‘Beyond Static Populations: Efficient Delay-Constrained Scheduling for Dynamic Users via Deep Reinforcement Learning,’’ Proceedings of the 26rd ACM International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing (MobiHoc), October 2025.
P. Hu, Y. Chen, L. Pan, Z. Fang, F. Xiao, L. Huang, “Multi-User Delay-Constrained Scheduling with Deep Recurrent Reinforcement Learning,” IEEE/ACM Transactions on Networking (TON), vol. 32, issue 3, pp. 2344-2359, June 2024.
Boning Li, Zhixuan Fang, Longbo Huang, “RL-CFR: Improving Action Abstraction for Imperfect Information Extensive-Form Games with Reinforcement Learning,” Proceedings of the Forty-first International Conference on Machine Learning (ICML), July 2024.
Yiqin Tan, Pihe Hu, Ling Pan, Jiatai Huang, Longbo Huang, “RLx2: Training a Sparse Deep Reinforcement Learning Model from Scratch,” Proceedings of the Eleventh International Conference on Learning Representations (ICLR), May 2023. (Spotlight)
L. Pan, L. Huang, T. Ma, H. Xu, “Plan Better Amid Conservatism: Offline Multi-Agent Reinforcement Learning with Actor Rectification,” Proceedings of the 39th International Conference on Machine Learning (ICML), July 2022.
L. Pan, T. Rshid, B. Peng, L. Huang, S. Whiteson, “Regularized Softmax Deep Multi-Agent Q-Learning,” Proceedings of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS), December 2021.
L. Pan, Q. Cai and L. Huang, ‘‘Softmax Deep Double Deterministic Policy Gradients,’’ Proceedings of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS), December 2020.
L. Pan, Q. Cai, Q. Meng, W. Chen, L. Huang, “Reinforcement Learning with Dynamic Boltzmann Softmax Updates,” Proceedings of International Joint Conference on Artificial Intelligence –Pacific Rim International Conference on Artificial Intelligence (IJCAI), July 2020.
L. Pan, Q. Cai and L. Huang, ‘‘Multi-Path Policy Optimization,’’ Proceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS), May 2020. (Selected for fast-track publication at JAAMAS, top 5%)
L. Pan, Q. Cai, Z. Fang, P. Tang, and L. Huang, “A Deep Reinforcement Learning Framework for Rebalancing Dockless Bike Sharing Systems,” Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI), Jan 2019.
Learning Theory and Distributed Training
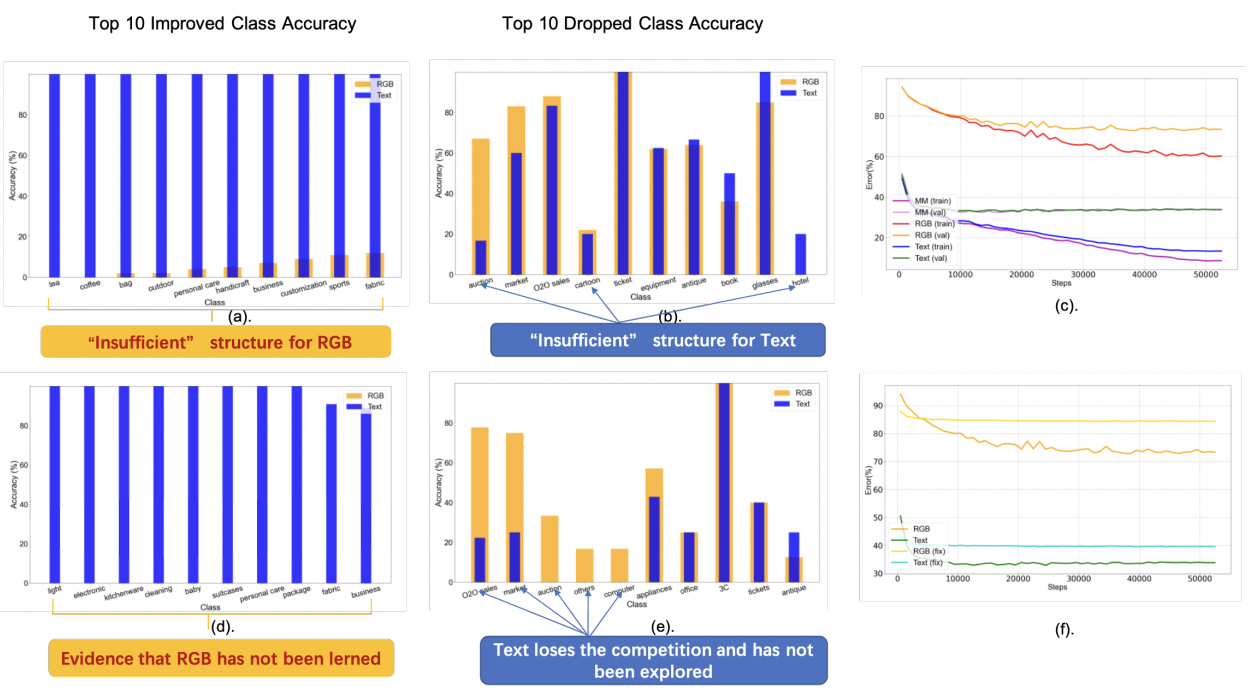
The rapid development of AI techniques have led to the invention of many powerful methods, which significantly outperform existing techniques. Yet, many of the phenomena observed in empirical studies are not fully understood. For instance, is multi-modality learning always better than single? Will training algorithms affect model performance?
In this thrust, we aim to investigate these important questions. We focus on building rigorous theoretical understanding for popular AI techniques and large-scale AI model training.
 |
Representative publications:
Xinran Gu, Kaifeng Lyu, Sanjeev Arora, Jingzhao Zhang, Longbo Huang, “A Quadratic Synchronization Rule for Distributed Deep Learning,” Proceedings of the Twelfth International Conference on Learning Representations (ICLR), May 2024.
Xinran Gu, Kaifeng Lyu, Longbo Huang, Sanjeev Arora, “Why (and When) does Local SGD Generalize Better than SGD?,” Proceedings of the Eleventh International Conference on Learning Representations (ICLR), May 2023.
Y. Huang, Y. Liang, and L. Huang, “Provable Generalization of Overparameterized Meta-learning Trained with SGD,” Proceedings of the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS), December 2022. (Spotlight)
Y. Huang, J. Lin, C. Zhou, H. Yang, L. Huang, “Modality Competition: What Makes Joint Training of Multi-modal Network Fail in Deep Learning? (Provably),” Proceedings of the 39th International Conference on Machine Learning (ICML), July 2022.
Y. Huang, C. Du, Z. Xue, X. Chen, H. Zhao, L. Huang, ‘‘What Makes Multimodal Learning Better than Single (Provably),’’ Proceedings of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS), December 2021.
Y. Yu, J. Wu and L. Huang, ‘‘Double Quantization for Communication-Efficient Distributed Optimization,’’ Proceedings of the Thirty-third Conference on Neural Information Processing Systems (NeurIPS), December 2019.
Diffusion and GFlowNets
Artificial Intelligence Generated Content (AIGC) has recently emerged as an important technique for creating content in various fields. However, existing methods often suffer from either high computational complexity or limited application scenarios. For example, diffusion methods often require heavy computation, making it challenging to adapt the technique to resource-limited applications.
In this thrust, our objective is to design efficient generative techniques, with an emphasis on diffusion and GFlowNets, two important methods that receive extensive attention.
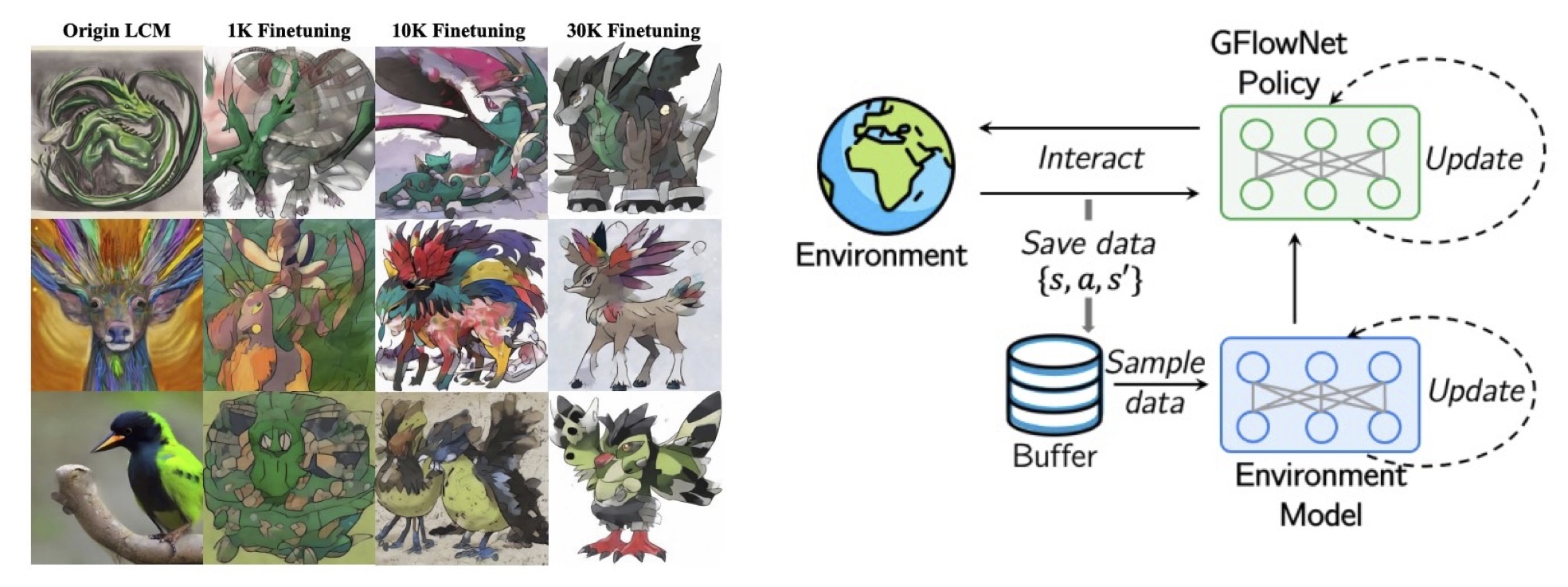 |
Representative publications:
Yuhao Liu, Yu Chen, Rui Hu, Longbo Huang, ‘‘Finite-Time Convergence Analysis of ODE-based Generative Models for Stochastic Interpolants,’’ Proceedings of the Fourteenth International Conference on Learning Representations (ICLR), April 2026.
Yuhao Liu, Yu Chen, Rui Hu, Longbo Huang, ‘‘Finite-Time Analysis of Discrete-Time Stochastic Interpolants,’’ Proceedings of Forty-second International Conference on Machine Learning (ICML), July 2025.
Rui Hu, Yifan Zhang, Zhuoran Li, Longbo Huang, ‘‘Beyond Squared Error: Exploring Loss Design for Enhanced Training of Generative Flow Networks," Proceedings of the Thirteenth International Conference on Learning Representations (ICLR), April 2025. (Spotlight)
Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick von Platen, Apolinário Passos, Longbo Huang, Jian Li, Hang Zhao, LCM-LoRA: A Universal Stable-Diffusion Acceleration Module, arXiv:2311.05556.
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao, Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference, arXiv:2310.04378.
Ling Pan, Dinghuai Zhang, Moksh Jain, Longbo Huang, Yoshua Bengio, “Stochastic Generative Flow Networks,” Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence (UAI), July 2023. (Spotlight)
Ling Pan, Dinghuai Zhang, Aaron Courville, Longbo Huang, Yoshua Bengio, “Generative Augmented Flow Networks,” Proceedings of the Eleventh International Conference on Learning Representations (ICLR), May 2023. (Spotlight)