ATCS ©C Learning and Prediction ©C Theory and Practice
2016 Spring
Lecturer: Jian Li
TA: Wei Cao fatboy_cw@163.com
Room: FIT bldg 1-222
time: every monday 1:30pm-3:55pm
ĪĪ
ĪĪ
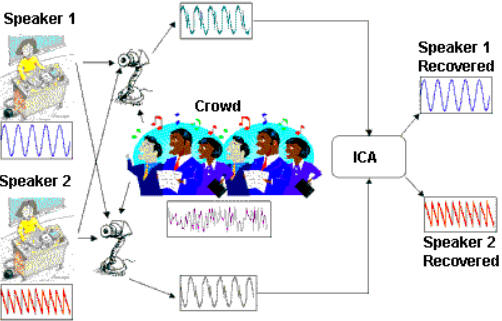
1. cocktail party problem: We are given a sample speech data consisting of people talking simultaneously in a room. How can we separate them? (check out independent component analysis)
We are given users' rates of a set of movies (as in the following matrix). But many entries of the matrix
is empty (the user didn't see/rate the movie). How can we predict the empty entries?
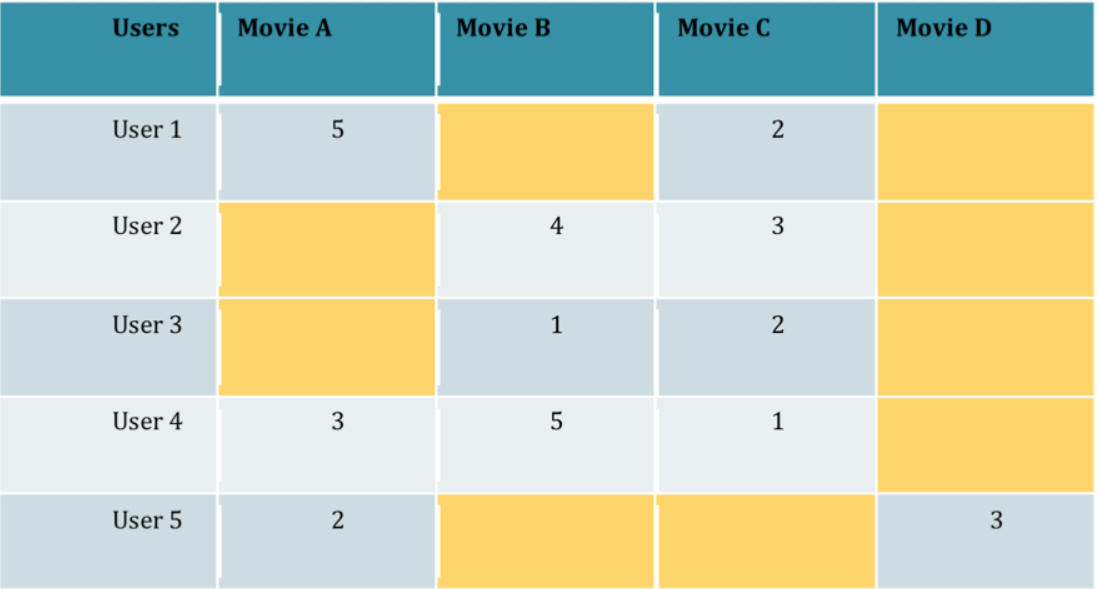
Check out Matrix completion, Collaborative filtering.
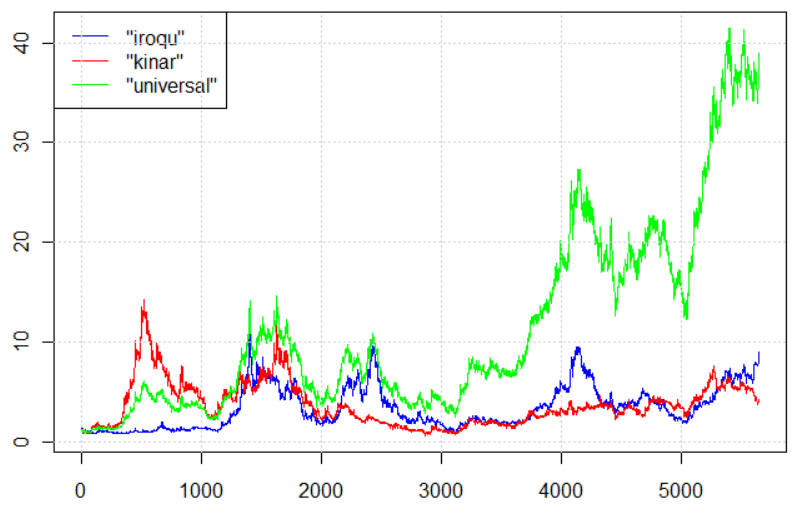
3. How to invest in a portfolio of stocks, such that you are no worse than investing the best stock in the long run?
(check out Universal Portfolio)
ĪĪ
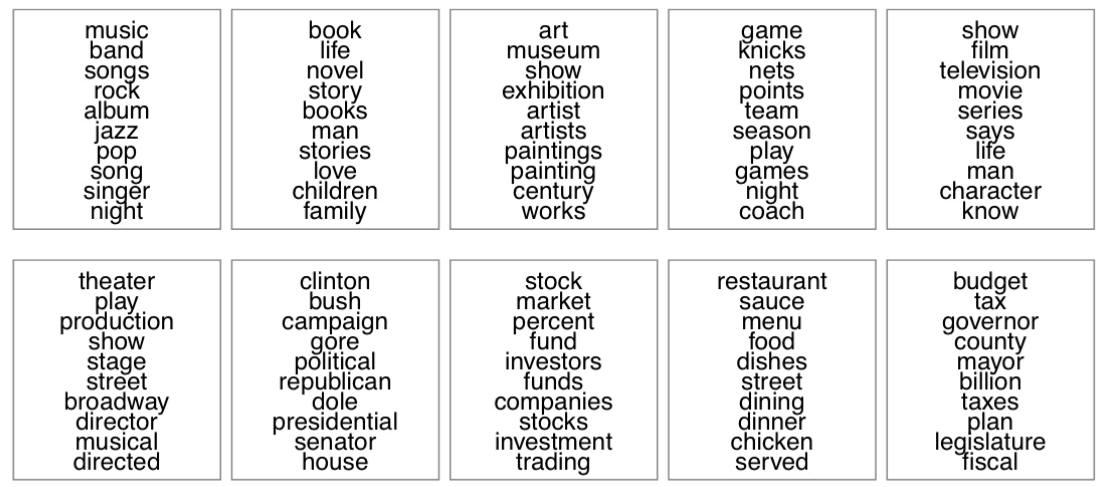
4. Given a collection of documents (newspaper article, twits, weibo, customer reviews...), how can we extract the topics (without knowning which topics they are about)?
ĪĪ
2. What is the answer of this? Man - Woman + King = ? Answer: Queue. (check out word2vec)
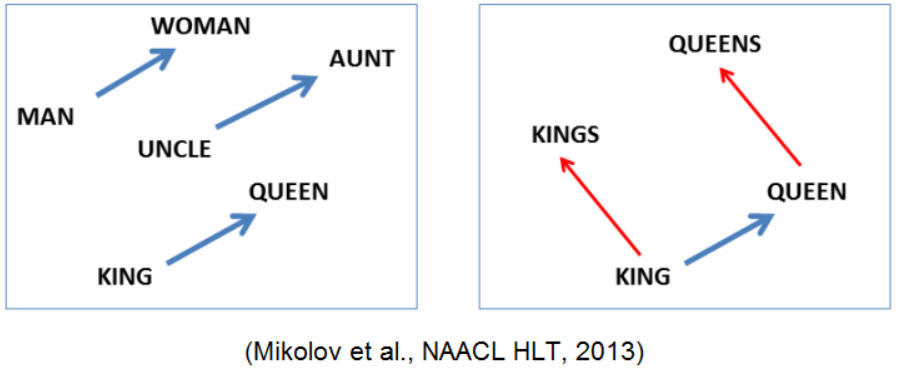
ĪĪ
3. What about this? 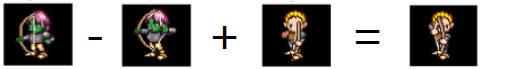 (Your
algorithm can generate the last fig! Check out
CNN+visual analogy)
(Your
algorithm can generate the last fig! Check out
CNN+visual analogy)
ĪĪ
ĪĪ
How can you use machine to generate hand-writing like this?
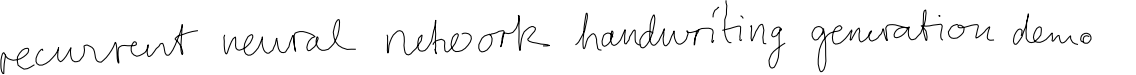
Try more examples in
http://www.cs.toronto.edu/~graves/handwriting.cgi?text=abc&style=&bias=0.15&samples=3
Check out RNN (LSTM)
Given an image, say something about it.

How to make your algorithm "paint" like a great artist!

ĪĪ
Inceptionism!



ĪĪ
We intend to cover a subset of the following topics (tentative):
(1) quickly recall basics about convex optimization, linear/logistic regression, regularization, newton method, stochastic gradient descent (asychronized, variance reduction method), generative vs discrimitive, variance vs bias
(2) Off-the-shelf machine learning and prediction algorithms: k-nn, SVM, kernel trick, clustering, Adaboost, gradient boosting, random forest, basic graphical models (including naive bayes, CRF, LDA)
(3) Online learning. Multi-armed bandit, Universal portfolio, Multiplicative weighting method
(4) linear algebra-based learning algorithms: SVD, principle
component analysis (PCA), independent component analysis (ICA), Nonnegative
matrix factorization (NMF), topic modeling, matrix completion, dictionary
learning, tensor method, spectral clustering
ĪĪ
(5) Deep learning: generative models like DBN, Back propagation, auto-encoder, most of time CNN and RNN (LSTM), neural turing machine, (attention-based?), MANY AMUZING APPLICATIONS, possibly some newest developments.
(Maybe): word2vec, hashing/sketching, multi-task learning, community detection,....
ĪĪ
Some knowledge about convex optimization may be useful. See JohnĪ»s class http://itcs.tsinghua.edu.cn/~john/convex2013.html and a previous course by myself. But it will be fine if you didn't take those courses.
The course is a blending of theory and practice. We will cover both the underlying mathematics and existing tools for quick and proper implementations. Writing code is a necessary part of this course.
Grading:
Schedule:
| Feb.22 | Brief review of probability (expectation, variance, covariance, concentration inequality, central limit theorem), Linear regression, SVD, PCA |
a PCA tutorial Further reading: The Singular Value Decomposition, Applications,and Beyond (PDF) by Zhihua Zhang (SJTU) |
| Mar.1 | Finishing PCA. Eigenface. Frequentist and Bayesian. Generative & discrimitive models. A probabilistic interpetation of linear regression, A bayesion approach to linear regress, regularization, Convex programming (basics, projected gradient descent, stochastic gradient descent). |
Eigenface paper
Asynchronous Stochastic Optimization Further reading: (A small monongraph) Convex Optimization: Algorithms and Complexity, by Bubeck (a classic textbook) S. Boyd and L. Vandenberghe, Convex Optimization |
| Mar.8 | Newton method, Logistic regression, perceptron, how to handle huge feature vectors (count-min sketch). | The Count-Min Sketch |
| Mar.14 | KKT condition, SVM, kernel trick, Geometry of SVM, Reproducing Hilbert Space, How to scale up kernel method (Random Fourier Features, Hashing) | Random Features for Large-Scale Kernel Machines Feature Hashing for Large Scale Multitask Learning Further reading: Duality and Geometry in SVM classifier Core Vector Machines Coreset for Polytope Distance |
| Mar.21 | Topic modeling. Nonnegative matrix factorization. Anchor
word assumption and an algorithm.
Conjugate prior (binomial/beta, multinomial/dirichlet), Dirichlet distributions. LDA (latent dirichlet distribution) and variants. |
Chapter 2 in lecture
notes (by Moitra)
Further reading: Learning Topic Models - Going beyond SVD |
| Mar. 28 | Independent Component Analysis
(Kurtosis, Negentropy, Mutual information)
Start Sparse Coding and Dictionary learning (LASSO, L0 and L1, compressive sensing, matching pursuit, othogonal matching pursuit) |
Independent Component Analysis: Algorithms and Applications The element of statistical learning, Ch 14.7 Further reading: Learning linear transformations Provable ICA with Unknown Gaussian Noise, and Implications for Gaussian Mixtures and Autoencoders For compressive sensing: the following chapter is a good starting point: http://statweb.stanford.edu/~markad/publications/ddek-chapter1-2011.pdf Notes from my previous course |
| Apr. 4 | Holiday, no class | ĪĪ |
| Apr. 11 |
(Mention)Some compressive sensing basics Mention (matrix completion, robust PCA) Sparse Coding and Dictionary learning K-SVD algorithm, online dictionary learning. how to use DL to denoise, image restoration CART-Classification or Regression Trees Start boosting. |
K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse
Representation Online dictionary learning for sparse coding Sparse representation for color image restoration CART: The element of statistical learning, Ch 9.2. Further reading: LASSO, Least angle regression: The element of statistical learning, Ch 3.4.4. Matrix completion: last Chapter in lecture notes (by Moitra) |
| Apr. 18 |
Adaboost,
mention( bootstrap, bagging) Gradient boosting, random forests. |
Additive models, Adaboost, gradient boosting:
The element of statistical learning, Ch 9 and 10 Random forest: The element of statistical learning, Ch 9 and 10 Further reading: Some learning theory about boosting: Foundation of Machine learning, Ch. 6. XGBoost: A Scalable Tree Boosting System
Explaining the Success of AdaBoost and Random Forests A lot of materials in Awesome Random Forest http://jiwonkim.org/awesome-random-forest/ |
| Apr. 26 | Start
Deep learning, BP, CNN (a brief intro to Theano, by Wei Cao) |
BP notes
http://cs231n.github.io/optimization-2/ Quick overiew of CNN http://cs231n.github.io/convolutional-networks/ Further reading: Visualizing and understanding CNN Lots of small training tricks in http://cs231n.stanford.edu/slides/winter1516_lecture5.pdf Practical Recommendations for Gradient-Based Training of Deep Architectures |
| May. 2 | No class (labor day) | ĪĪ |
| May. 9 |
Visualizing higher layers of CNN (Deconvnet), some CNN architechtures
(Alexnet, GoogleNet, ResNet). RNN, LSTM |
Visualizing and understanding CNN Deep Residual Learning for Image Recognition, Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun http://cs231n.stanford.edu/slides/winter1516_lecture10.pdf Further reading: RNN chapter in the deep learning book VISUALIZING AND UNDERSTANDING RECURRENT NETWORKS Awesome RNN https://github.com/kjw0612/awesome-rnn An online RNN tutorial |
| May. 16 | Word2Vec, Glove, deepwalk | Distributed Representations of Words
and Phrases and their Compositionality Glove: Global vectors for word representation. DeepWalk: Online Learning of Social RepresentationsFurther reading: INFINITE DIMENSIONAL WORD EMBEDDINGS, Nalisnick, Ravi Swivel: Improving Embeddings by Noticing What's MissingRandom Walks on Context Spaces: Towards an Explanation of the Mysteries of Semantic Word Embeddings. |
| May. 23 | Image
reconstruction Deepdream Neuralstyle Neural Turing Machine |
Understanding Deep Image Representations by Inverting ThemA Neural Algorithm of Artistic Style GitHub - google/deepdream (bat-country)Neural Turing Machines, arXiv preprint arXiv:1410.5401, A.Graves, G. Wayne, and I. Danihelka. Further reading: EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES |
| May. 30 |
End-to-End memory network (for Q&A) (by Wei Cao) Deep learning for video processing/understanding (by Chuang Gan) |
[1503.08895] End-To-End Memory NetworksĪĪ |
| Jun. 4 | Deep
Reinforcement Learning: Basics of RL, MDP, Value iteration, policy iteration, Q-learning, Combining DNN with policy gradient, DAGGER |
Some classical method for MDP (value iteration, policy iteration, LP)Q-learning : Neuro-Dynamic Programming, Ch 5.6A Reduction of Imitation Learning and Structured Prediction to No-Regret Online LearningA good blog post on Policy Gradient by Andrej Karpathy Further reading:RL course by David Silver Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning (code and videos) Slides on Deep Q-learning Awesome Reinforcement LearningĪĪ |
Related papers (under construction..):
Universal Portfolios, Thomas Cover
Universal Portfolios With and Without Transaction Costs, Avrim Blum, Adam Kalai.
The Multiplicative Weights Update Method: a Meta-Algorithm and Applications, Sanjeev Arora, Elad Hazan, Satyen Kale
An Empirical Exploration of Recurrent Network Architectures
Deep Visual Analogy-Making, by ScottReed Yi Zhang Yuting Zhang Honglak Lee
Deep Visual-Semantic Alignments for Generating Image Description, Andrej Karpathy and Li Fei-Fei
Striving for Simplicity: The All Convolutional Net, Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, Martin Riedmiller
Spatial Transformer Networks: Max Jaderberg Karen Simonyan Andrew Zisserman Koray Kavukcuoglu
FractalNet: Ultra-Deep Neural Networks without Residuals
References:
[Book] The elements of statistical learning
[Book] Pattern recognition and machine learning
[Book] Probabilistic Graphical Models
Alex SmolaĪ»s class at CMU http://alex.smola.org/teaching/cmu2013-10-701x/
Andrew NgĪ»s class at Stanford https://www.coursera.org/learn/machine-learning
Nando de FreitasĪ»s class at Oxford https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/
Carlos Guestrin / Emily FoxĪ»s class at UW http://courses.cs.washington.edu/courses/cse599c1/13wi/lectures.html
Richard Socher's course at Stanford: http://cs224d.stanford.edu/index.html
Feifei Li, Andrej Karpathy and Justin Johnson's class at Standford: http://cs231n.stanford.edu/
Ankur Moitra's (MIT) lecture notes (Algorithmic machine learning) lecture notes
Python is the default programming language we will use in the course.
If you haven't use it before, don't worry. It is very easy to learn (if you know any other programming language), and is a very efficient language, especially
for prototyping things related scientific computing and numerical optimization. Python codes are usually much shorter than C/C++ code (the lauguage has done a lot for you). It is also more flexible and generally faster than matlab.
A standard combination for this class is Python+numpy (a numeric lib for python)+scipy (a scientific computing lib for python)+matplotlab (for generating nice plots)
Another somewhat easier way is to install Anaconda (it is a free Python distribution with most popular packages).
ĪĪ
ĪĪ
ĪĪ
ĪĪ
ĪĪ